Why Model Architecture Matters
Every neural network is, at some level, a function that takes numbers in and produces numbers out. The weights are adjusted during training until the function approximates the label data. This is true of a network with three layers and a thousand parameters and of a model with a hundred billion: The mathematics is the same.
What differs between networks is how the architecture allows adjustment. Every architectural choice encodes an assumption about the structure of the problem. Get the assumption right and the network learns efficiently from relatively little data. Get it wrong and no amount of training rescues it. This is what researchers term “inductive bias”: the architecture imposes choice before a single weight is updated.
The history of deep learning is a history of progressively better architectures.
Feed-forward networks
A feed-forward network connects every input to every neuron in the first layer, every neuron in the first layer to every neuron in the second, and so on to the output. Every connection has a learned weight. The network makes no assumption about which inputs are related to which outputs, or whether the relationship between them has any structure worth exploiting.
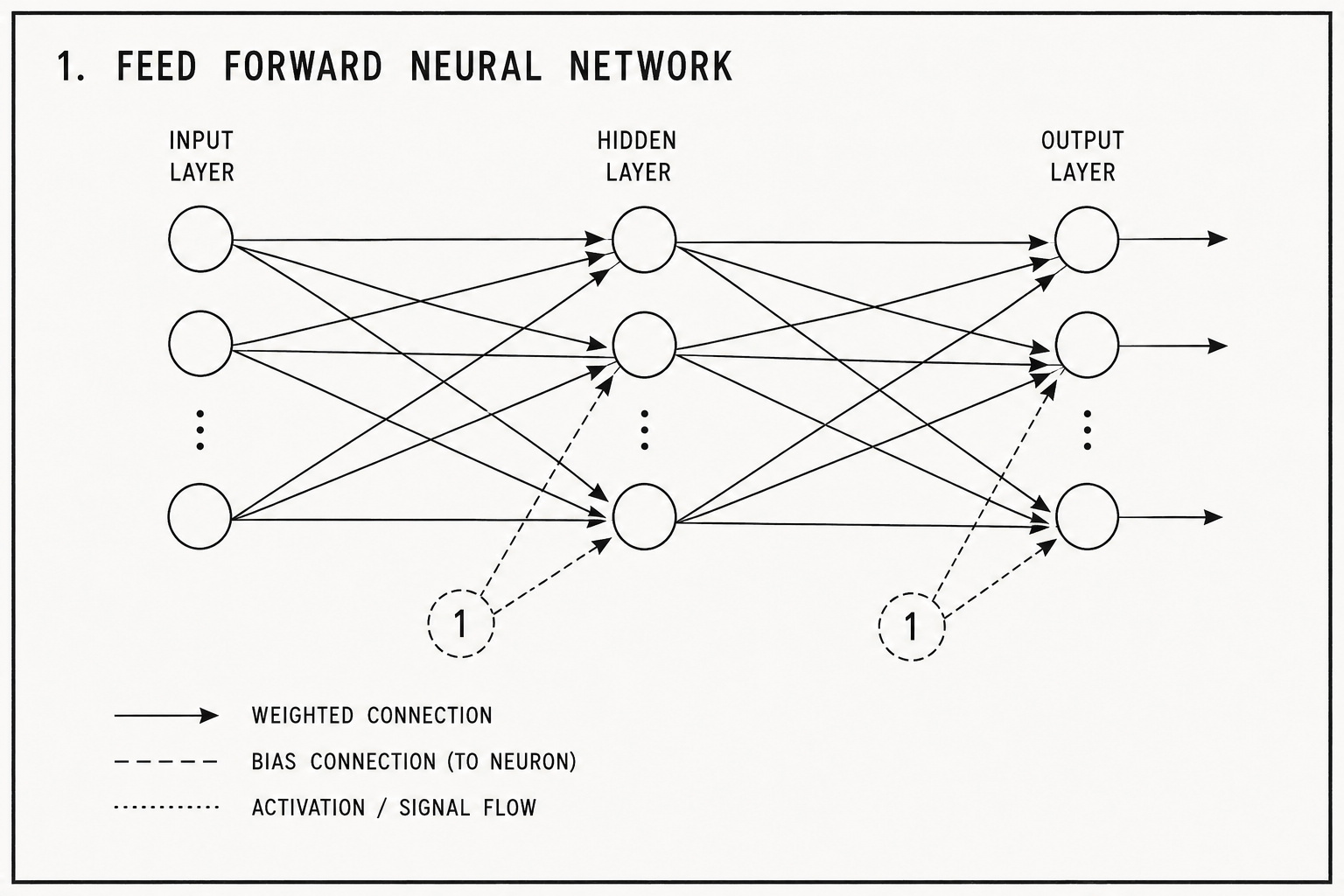
For tabular data – a row of measurements where each column is a distinct feature – this is a reasonable prior. There is no spatial or sequential structure to exploit. The network learns what it can from the correlations in the data.
For images it fails immediately. A 256x256 pixel image has 65,536 inputs. A feed-forward network would need millions of weights just to connect the input to the first hidden layer, and would learn those connections from scratch with no prior that nearby pixels are more likely to be related than distant ones, and no prior that a pattern in one corner of the image should behave the same way in another. The network could in principle learn these things. In practice the data requirement is too large and the training signal too diffuse.
The architecture learns weights. It does not learn where those weights apply, or whether any given weight is relevant to any given input.
Convolutional neural networks
The convolutional neural network encodes two assumptions. Local spatial relationships matter: a pixel is more likely to be related to its neighbours than to pixels far away. And the same local pattern can appear anywhere in the image and should be recognised wherever it appears.
These assumptions take the form of a kernel: a small grid of weights slid across the image, applying the same computation at every position. The network learns what patterns to look for. It does not learn where to look, or whether to apply a given kernel to a given location. Routing is fixed by the architecture; the learned weights fill in the content.
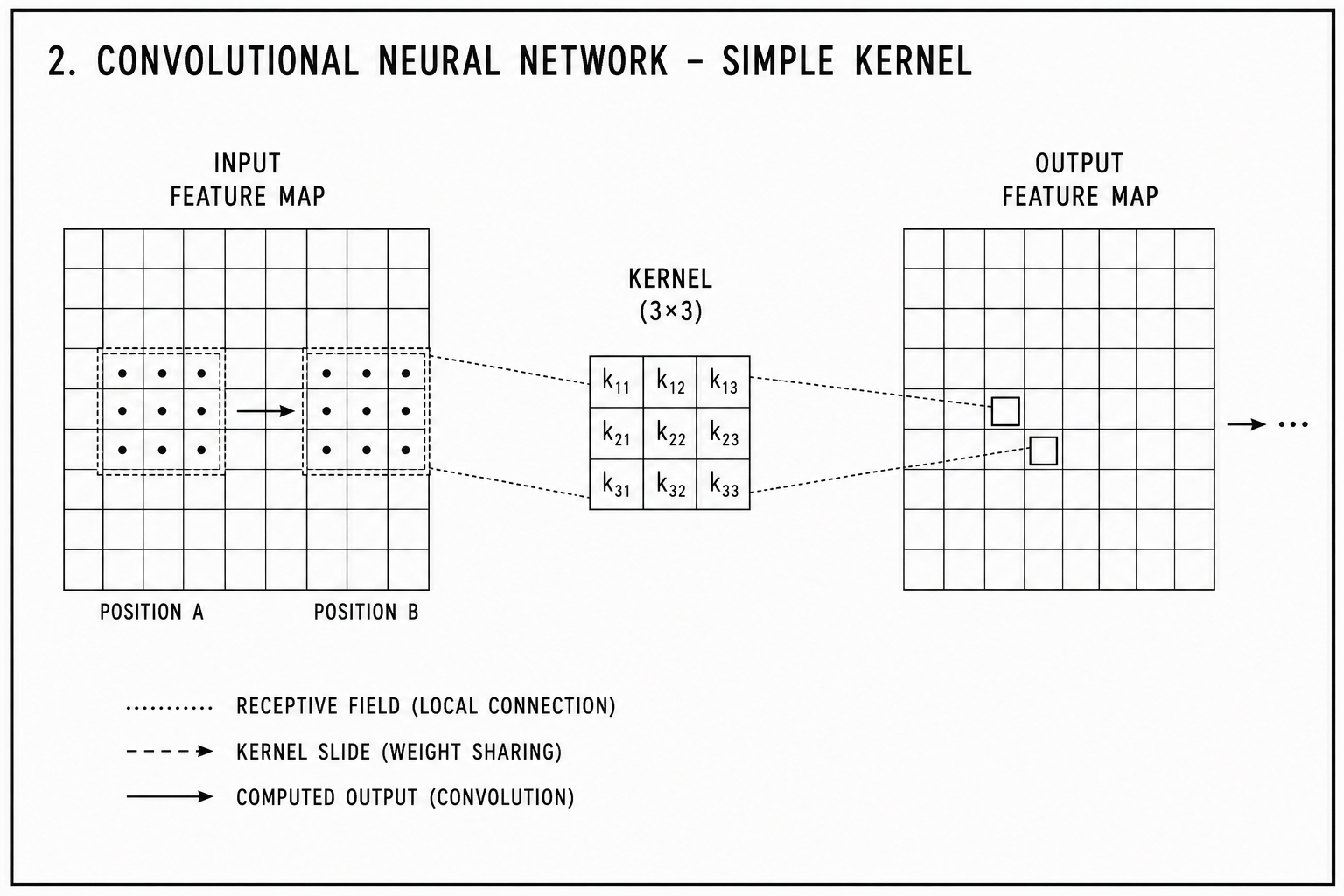
For images, this prior is correct. AlexNet (Krizhevsky et al., 2012) demonstrated the payoff: trained on ImageNet on a GPU, it halved the classification error against methods that had improved incrementally for a decade. The architecture’s assumption matched the structure of the data.
The limitation is the same thing that made it powerful. Every input passes through the same learned filters in the same order. A filter that detects edges detects them everywhere, regardless of whether edges are relevant to the current input. The network has no mechanism for deciding at runtime that this image requires different processing from that one.
For language this assumption fails entirely. Words derive meaning from context, and the relevant context for any given word can be anywhere in the sentence – the beginning, the end, several clauses away. A fixed local filter cannot reach it.
Transformers
The transformer (Vaswani et al., 2017) removes the fixed routing assumption. Rather than applying the same operation to every position, it computes for each position which other positions are relevant to it right now. The query-key-value mechanism does this: the query encodes what the current position is looking for, the keys encode what each other position offers, and the dot product between them determines how much attention to pay. The routing pattern is computed from the content of the input, fresh for each forward pass.
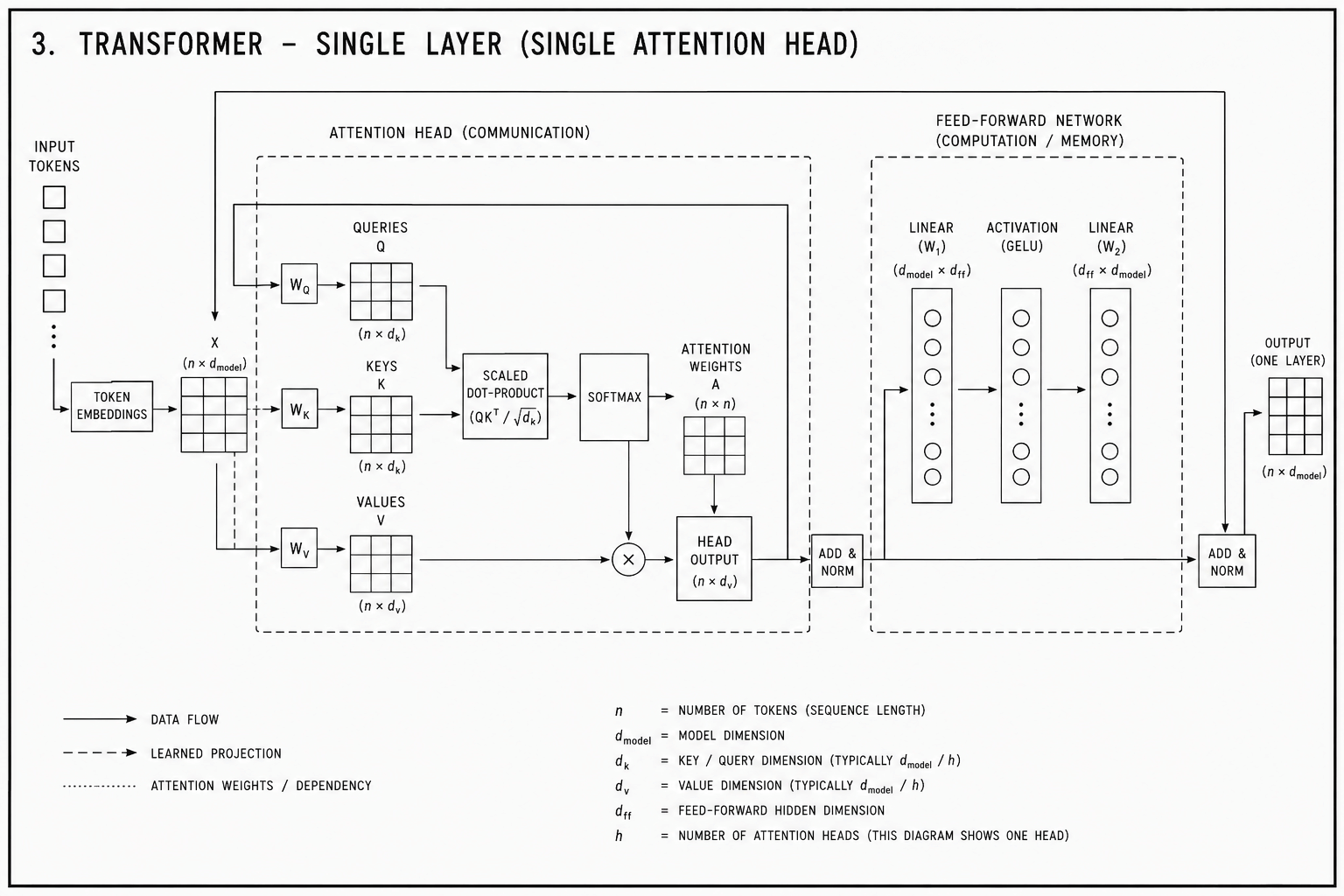
The CNN learns what patterns to look for. The transformer learns what patterns to look for and how to route information between positions based on what it finds. The inductive bias is weaker – the transformer imposes less prior structure – which makes it slower to train on small datasets but considerably more general.
A transformer block has two distinct components. The attention mechanism routes: it moves information between positions based on relevance. The feed-forward network (FFN) remembers: applied independently to each position, it stores and retrieves knowledge. Research (Geva et al., 2021) has shown that the FFN functions as a key-value memory – the first layer recognises patterns, the second retrieves associated content. Factual knowledge lives in the FFN weights. Relational structure lives in the attention weights.
The CNN learned weights. The transformer learns weights and routing.
Mixture of experts
A dense transformer applies every FFN layer to every token. The attention routing is dynamic, but the memory retrieval is not: the full cost of every FFN weight is paid for every input, regardless of how much of that knowledge is relevant to the current token.
Mixture-of-experts (MoE) architectures replace the single FFN in each block with N expert FFNs and a learned router. For each token, the router selects a small number of experts – typically two from a pool of eight or more – and only those run. Total parameter count scales with N. Compute per token stays constant. Mixtral 8x7B (Mistral AI, 2023) has 47 billion total parameters and 13 billion active per token: the knowledge capacity of a large model at the inference cost of a much smaller one.
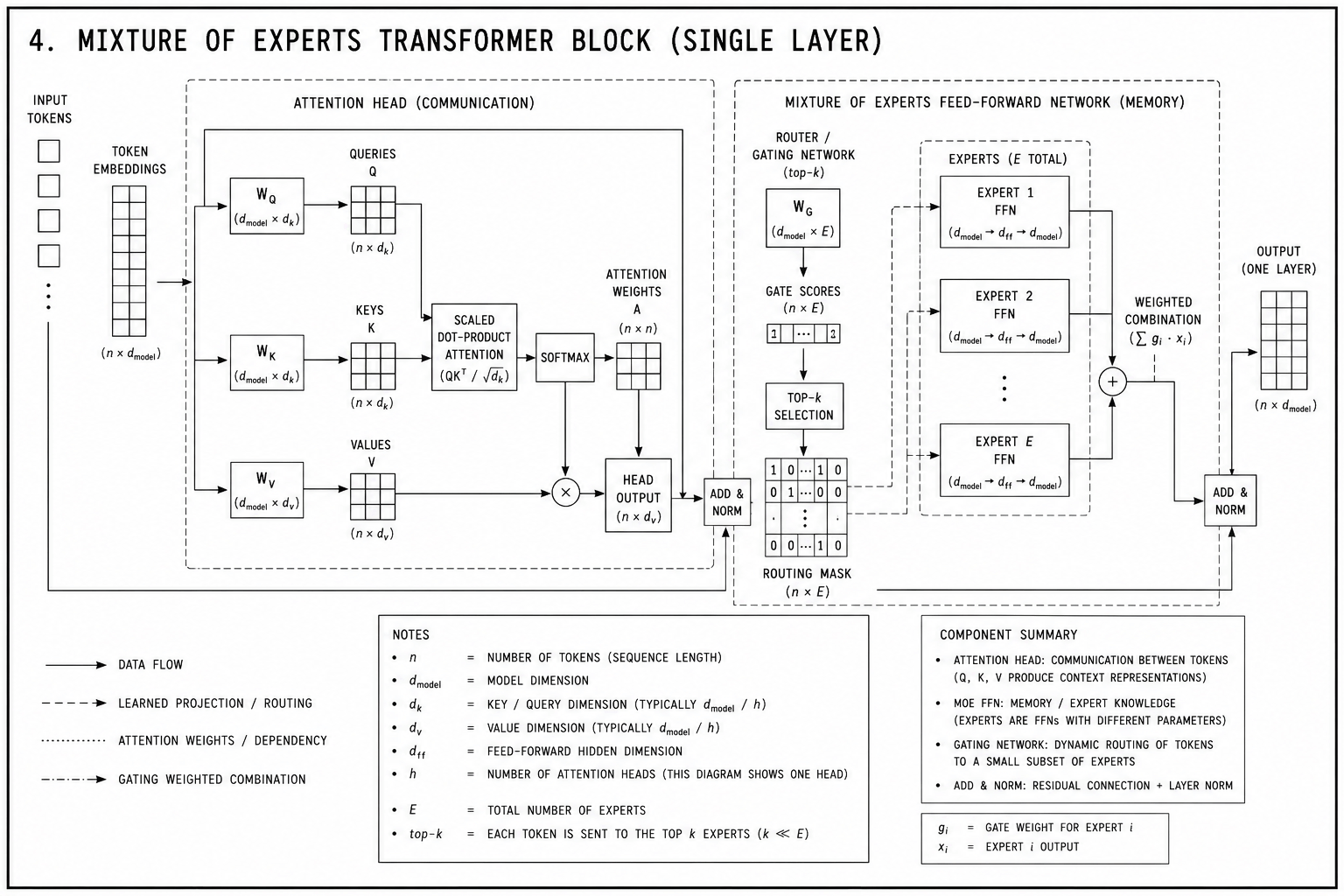
The experts specialise through training pressure rather than architectural constraint. No rule assigns expert 4 to grammar and expert 7 to chemistry. They diverge because the router, trained jointly with the experts, finds that routing similar inputs to the same expert reduces prediction error. The model learns to partition its own knowledge.
The transformer learned weights, routing, and – implicitly – which knowledge was relevant to which inputs. MoE makes that last step explicit and tunable.
The separation problem
The functional distinction between attention and FFN – routing versus memory – has prompted a practical question: if those functions are genuinely distinct, can they be separated and managed independently?
LoRA (Hu et al., 2021) approaches this from the adaptation side. Rather than retraining a model’s full weights for a new task, it freezes them and injects small trainable matrices alongside the attention projections. The assumption is that the update required for a new task occupies a low-rank subspace of the weight matrix – that new knowledge is compact enough to be expressed without disturbing the existing weights. This holds often enough to be practically useful, and it implies something about the structure of what is stored: knowledge in a trained model is more separable than the joint training process suggests.
MoE points in the same direction from the architecture side. If expert FFNs specialise by domain, they can in principle be replaced: train a base model, swap the expert weights for domain-specific ones, leave the attention layers unchanged. The routing stays; the memory changes.
The difficulty is that the router was trained against the original experts. Replace the experts and the routing is suboptimal for the new knowledge. The separation that looks clean in the diagram is entangled in the training history. The attention and FFN weights are trained jointly against the same loss, so the boundary between relational structure and stored fact blurs in ways the architecture does not reveal.
LoRA names the assumption that the boundary exists. MoE names the aspiration that it can be exploited. Neither has fully delivered a training procedure that produces a clean separation. That remains an open problem – and probably the most architecturally interesting one currently on the table.