The Algorithm Lottery
The YouTube channel in the screenshot has not been uploaded to in years. No new content, no replies, no scheduled releases. At some point in early 2024 the algorithm selected one of its videos and sent it to several thousand people. Watch time accumulated. Seven subscribers arrived. Then it went quiet again.
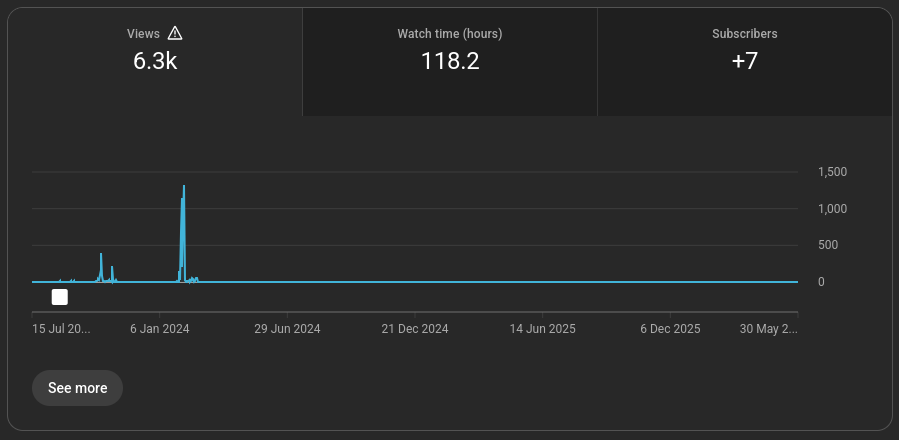
This is not an anomaly. It is how recommendation systems manage one of their central problems.
A recommendation engine optimises on engagement signals: watch time, clicks, shares, return visits. In the early life of a platform, there is enough novelty in the content pool that the system keeps discovering new things that work. Over time, the feedback loop tightens. Content that performed well gets recommended, generates more signal, and gets recommended again. The system learns what its current audience engages with and serves more of it. Left to run, this process converges: the feed becomes a reflection of itself, the audience stops encountering anything outside its established taste profile, and engagement eventually stagnates.
The standard term for this in machine learning is the explore-exploit tradeoff. A model that only exploits its existing knowledge stops learning about the distribution it is supposed to represent. Recommendation systems are no exception. The correction is to deliberately sample outside the high-confidence region – to surface content the system does not yet have strong signal on, show it to a test audience, and observe what happens. If the engagement is there, a new audience cluster gets mapped. If it is not, the experiment ends quietly. (The same problem in a training data context is covered in Sampling Strategies for Imbalanced Data.)
The dormant channel was one such experiment. Its video sat in a part of the content space the algorithm had not recently probed. The system selected it, sent it to a few thousand people who fit a plausible profile, and measured the result. Seven subscribers and 118 hours of watch time is a real signal, even if it is not a large one. The channel did not grow because it had maintained a presence or stayed visible. It grew because the content was worth finding, and the system eventually went looking.
This reframes the standard advice about posting cadence. Consistent publishing does increase the volume of content available to be sampled, and more content means more surface area for an exploratory probe to land on. But the selection is a test for latent engagement, not a reward for showing up regularly. A video produced to fill a posting slot and a video that answers a specific question clearly are both eligible for selection. They are not equally likely to survive it.
The same logic applies across platforms. Search indices, open-source repositories, article aggregators – any system that surfaces content to audiences it has not fully characterised will periodically test underexplored material. Search Console data makes this visible directly: queries arrive at pages months or years after publication, in patterns unrelated to when the content was promoted. The index found it when it needed new signal, not when the author was paying attention.
The practical implication is straightforward. Publishing things worth finding is the correct strategy, not because patience is a virtue, but because the system is actively trying to find them. The selection will come when the algorithm needs to probe that part of the space. What determines the outcome is whether the content survives the test.