Reheat: Intent Clustering for Google Search Console
Search Console shows which queries arrived. The intent behind those queries – how they cluster, which clusters dominate impressions, and how your content is spread among those clusters – is unreadable. Reheat makes it readable.
Reheat is an open-source Python CLI that pulls query data from Search Console, embeds each query as a vector, clusters by semantic intent, and produces a ranked report of content gaps and opportunities.
Installation and setup
pip install reheat
Configure a Search Console source with your OAuth2 credentials:
reheat sources create \
--source-type google_search_console \
--domain yourdomain.com \
--client-secrets-path ~/.reheat/google-search-console.json
reheat sources auth
This opens a browser for the Google OAuth2 consent flow. The token persists and refreshes automatically on subsequent runs.
The pipeline
Each stage enriches the previous output and writes to the state file. An interrupted run resumes from the last completed stage.
reheat runs create # fetch queries from Search Console
reheat enrich tags # tag queries by type
reheat enrich embed # embed each query locally via fastembed
reheat enrich cluster # k-means clustering (default: 32 clusters)
reheat enrich gap # score content coverage per cluster
reheat analyse opportunities
reheat project create
reheat report scatter create
reheat report summary create
reheat report coverage create
reheat serve
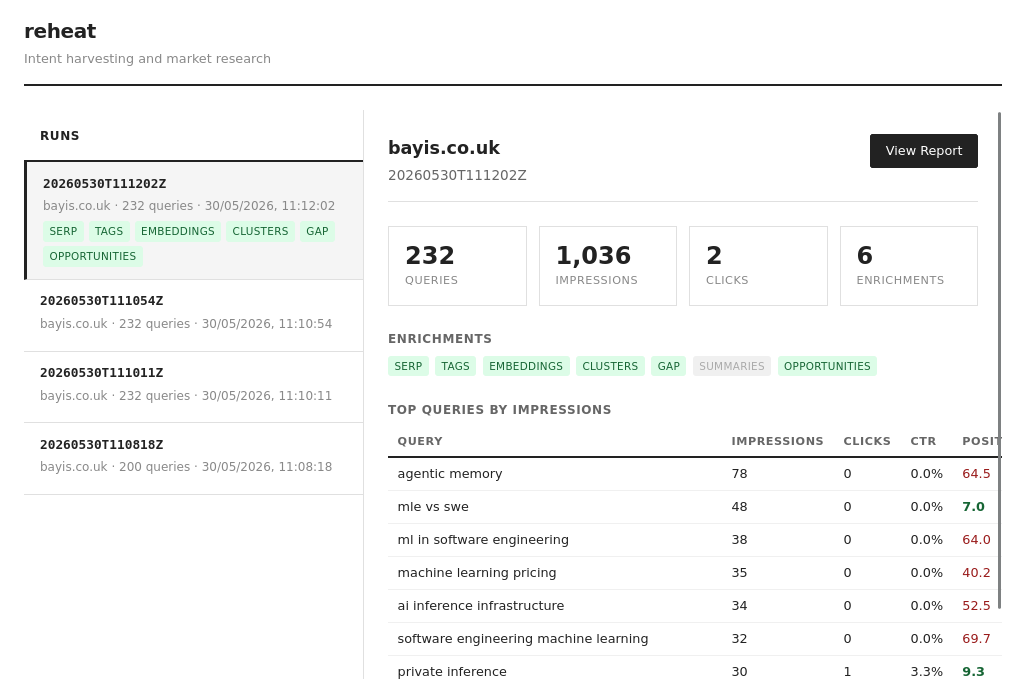
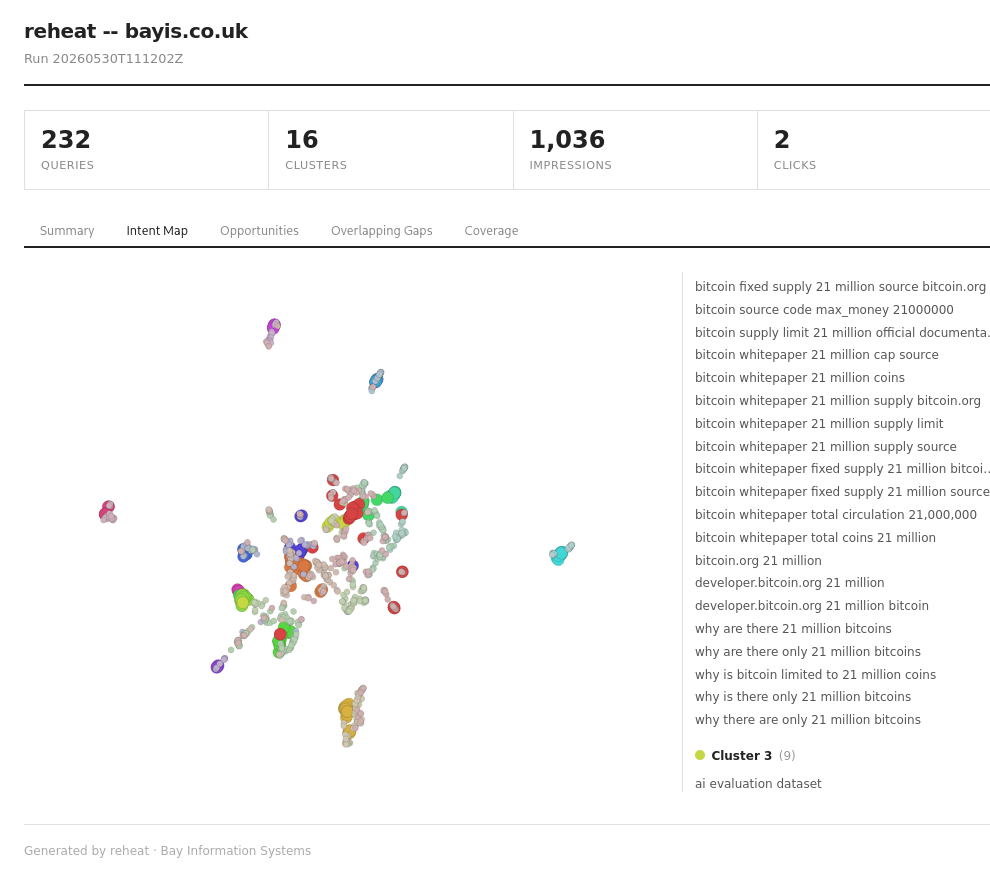
Open http://localhost:8000. The scatter plot shows the full intent landscape. The summary panel identifies performing and underserved clusters. The opportunities table ranks gaps by impression potential.
Against the bayis.co.uk content library: 232 queries, 106 SerpAPI enrichments, 16 intent clusters, 430 ranked opportunities.
How it works
Embedding runs locally via fastembed. Clustering uses k-means; the cluster count defaults to 32 and is configurable. Each cluster receives a natural language label from an inference provider – OpenAI, Anthropic, or Marigold, the private inference API under development at Bay Information Systems. Credentials load automatically from a .env file.
An optional SerpAPI enrichment pass pulls related queries and People Also Ask results into the same embedding space, widening the cluster model’s view of the intent landscape around your existing queries.
Persistence
Reheat uses dynawrap, a key-value library with a consistent interface over a local JSON file, PostgreSQL, and DynamoDB. The default backend is a JSON file at ~/.reheat/state.json. Switching to PostgreSQL or DynamoDB is a configuration change; the pipeline stays identical. The architecture is deliberate: local use today, multi-user hosted deployment later, same codebase throughout.
Links
- GitHub: github.com/bayinfosys/reheat
- PyPI: pypi.org/project/reheat
- Docs: bayinfosys.github.io/reheat